If we have two variables, A and B, we can compute a Pearson's r for them. Knowing how many samples we have, we can use a lookup table to find a p value. So, assuming good data (taken using a reliable measurement instrument from a representative sample), what does this p value tell us? Specifically, is it the probability of none of the following being true:
Changes in A cause changes in B,
OR
Changes in B cause changes in A,
OR
There is some variable C, and changes in C cause changes in A and B?
Are there other possibilities? In short, is a statistically significant correlation "acceptably" likely to imply one of the above types of causation, assuming decent sampling but no imposition of treatment, or are there other complications?
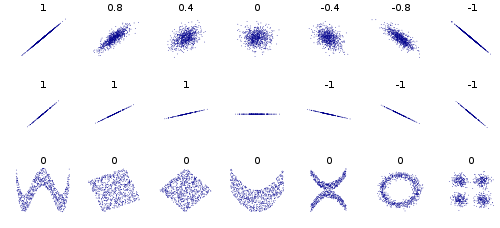
Best Answer
I'm simplifying a little bit, but basically: the p-value that you're probably referring to denotes the probability that, given a particular sample size, two random sets of numbers will have a correlation greater than or equal to the one you've observed.
Example: Say we roll a pair of dice 6 times. This generates 6 unique x,y points. If the order of the rolls doesn't matter, what are the chances that you'd end up with the following points:
1,1; 2,2; 3,3; 4,4; 5,5; 6,6?
Pretty low, right? This dataset has a correlation coefficent of 1 and an n of 6. If you look up the associated p-value, you'll find it's < 0.00001. There is less than 0.00001% chance that these numbers are simply random dice rolls.
Now for some actual dice rolls - here's numbers I generated randomly in excel:
1,6; 2,3; 3,4; 3,2; 5,2; 6,4; .
The correlation coefficient of this data set is = 0.1806. Again, the sample size is 6. The associated p-value for a two-tailed test is 0.3660225.
If these were data from an experiment, we'd say that the association between x and y is so weak that it could be adequately described by random chance. In fact, we'd say that there is a 36.6% chance that there is no true treatment effect, and that the (weak) observed correlation is simply due to random chance.
A significant correlation does not necessarily imply causation. To determine whether there is a causal relationship, you must use a randomized experiment. That is one reason why tobacco companies were so difficult to prosecute in the 1960's - no scientists were "randomly assigning" humans to be smokers or non-smokers, then waiting to see who got lung cancer. The prosecutor's primary evidence came from came from observational studies, with no randomized treatments. However, after decades of strong correlation between smoking and lung cancer, along with plausible medical explanations for how tobacco smoking harms the body, courts were finally convinced that smoker's lung cancer was caused by smoking and not something else. Statisticians are the same way - in the absence of experimental data, causation is only implied by strong, repeated, and prolonged correlations, usually with a plausible mechanism for how x might be acting on y.
This page might be helpful if you're still wrapping your head around correlation coefficients.
To learn more about one- vs. two-tailed tests, check this wikipedia page.