The cost function used with the sigmoid function was motivated by the maximum likelihood estimation, and $$\text{cost}=−y\log(h_0(x))−(1−y)\log(1−h_0(x))$$ is just another way of saying $$\text{cost}=−log(h_0(x))$$ when $y=1$ and $$\text{cost}=−\log(1−h_0(x))$$ when $y=0$.
Those motivations still exist no matter what the activation function is (sigmoid or hyperbolic tangent). I would map the hyperbolic function from the range (-1,1) to the same range as the sigmoid (0,1) so that:
$$\text{cost} = −\frac{y+1}{2} \log{\left(\frac{h_\theta(x)+1}{2}\right)}−(1− \frac{y+1}{2})\log\left(1−\frac{h_\theta(x)+1}{2}\right)$$
Where $$h_\theta = \tanh\left(\frac{2}{3}x \right)$$.
This will have a different gradient than the sigmoid. Good luck.
The cost function of a neural network is in general neither convex nor concave. This means that the matrix of all second partial derivatives (the Hessian) is neither positive semidefinite, nor negative semidefinite. Since the second derivative is a matrix, it's possible that it's neither one or the other.
To make this analogous to one-variable functions, one could say that the cost function is neither shaped like the graph of $x^2$ nor like the graph of $-x^2$. Another example of a non-convex, non-concave function is $\sin(x)$ on $\mathbb{R}$. One of the most striking differences is that $\pm x^2$ has only one extremum, whereas $\sin$ has infinitely many maxima and minima.
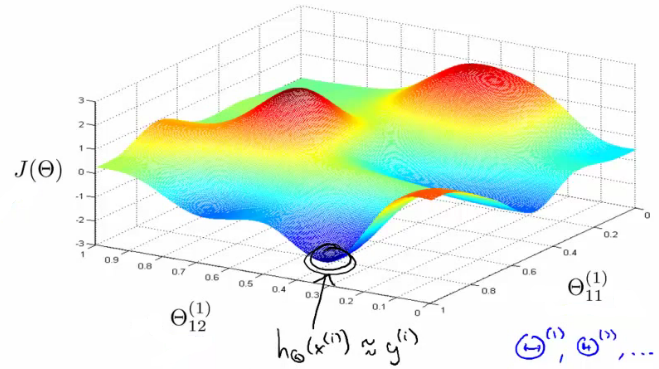
How does this relate to our neural network? A cost function $J(W,b)$ has also a number of local maxima and minima, as you can see in this picture, for example.
The fact that $J$ has multiple minima can also be interpreted in a nice way. In each layer, you use multiple nodes which are assigned different parameters to make the cost function small. Except for the values of the parameters, these nodes are the same. So you could exchange the parameters of the first node in one layer with those of the second node in the same layer, and accounting for this change in the subsequent layers. You'd end up with a different set of parameters, but the value of the cost function can't be distinguished by (basically you just moved a node, to another place, but kept all the inputs/outputs the same).
{kind=link}
Best Answer
The cross entropy of an exponential family is always convex. So, for a multilayer neural network having inputs $x$, weights $w$, and output $y$, and loss function $L$
$$\nabla^2_y L$$
is convex. However,
$$\nabla^2_w L$$
is not going to be convex for the parameters of the middle layer for the reasons described by iamonaboat.