This question arises from my actual confusion about how to decide if a logistic model is good enough. I have models that use the state of pairs individual-project two years after they are formed as a dependent variable. The outcome is successful (1) or not (0). I have independent variables measured at the time of formation of the pairs. My aim is to test whether a variable, which I hypothesized would influence the success of the pairs has an effect on that success, controlling for other potential influences. In the models, the variable of interest is significant.
The models were estimated using the glm() function in R. To assess the quality of the models, I have done a few things: glm() gives you the residual deviance, the AIC and the BIC by default. In addition, I have calculated the error rate of the model and plotted the binned residuals.
- The complete model has a smaller residual deviance, AIC and BIC than the other models that I have estimated (and that are nested in the complete model), which leads me to think that this model is "better" than the others.
- The error-rate of the model is fairly low, IMHO (as in Gelman and Hill, 2007, pp.99):
error.rate <- mean((predicted>0.5 & y==0) | (predicted<0.5 & y==1), at around 20%.
So far so good. But when I plot the binned residual (again following Gelman and Hill's advice), a large portion of the bins fall outside of the 95% CI:
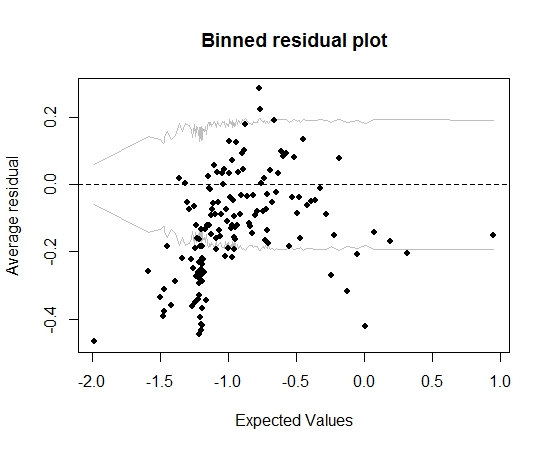
That plot leads me to think there is something utterly wrong about the model. Should that lead me to throw the model away? Should I acknowledge that the model is imperfect but keep it and interpret the effect of the variable of interest? I have toyed around with excluding variables in turn, and also some transformation, without really improving the binned residuals plot.
Edit:
- At the moment, the model has a dozen predictors and 5 interaction effects.
- The pairs are "relatively" independent of each other in the sense that they are all formed during a short period of time (but not stricly speaking, all simultaneously) and there are a lot of projects (13k) and a lot of individuals (19k), so a fair proportion of projects are only joined by one individual (there are about 20000 pairs).
Best Answer
Classification accuracy (error rate) is an improper scoring rule (optimized by a bogus model), arbitrary, discontinuous, and easy to manipulate. It's not needed in this context.
You didn't state how many predictors there were. Instead of assessing model fit I would be tempted to just make the model fit. A compromise approach is to assume that interactions aren't important and to allow continuous predictors to be nonlinear using regression splines. Plot the estimated relationships. The
rmspackage in R makes all this relatively easy. See http://biostat.mc.vanderbilt.edu/rms for more information.You might elaborate on "pairs" and whether your observations are independent.