Updated in order to address @mrgloom's comment
In my original answer, I stated that VGG-16 has roughly 138 million parameters and ResNet has 25.5 million parameters and because of this it's faster, which is not true. Number of parameters reduces amount of space required to store the network, but it doesn't mean that it's faster. Resnet is faster than VGG, but for a different reason.
Also, as @mrgloom pointed out that computational speed may depend heavily on the implementation. Below I'll discuss simple computational case. Also, I'll avoid counting FLOPs for activation functions and pooling layers, since they have relatively low cost.
First of all, speed of the convolution will depend on the size of the input. Let's say you have gray colored (1 channel) 100x100 image and you apply one 3x3 convolution filter with stride 1 and 0 padding. This operation will require you ~163k FLOPs. It's easy to calculate. If you know how convolution works you should know that from the 100x100 image you will get 98x98 (using the setup described above). And in order to compute each value from the 98x98 output image you need to do 9 multiplications and 8 additions, which in total corresponds to 17 operations per value. If you combine everything you get 98 * 98 * 17 and it equals to 163,268. Now, imagine you apply the same filter on the larger image, let's say 200x200. Image has 4 times bigger area and therefor you'll get roughly 4 times more FLOPs.

Now, I'll start with the comparison between VGG19 and Resnet 34, since that's the image that they use in the original paper.
In the figure 3, they break down architecture into the set of blocks marked with different colors. At the end each block reduces height and width by a factor of two. In the first two layers Resnet manages to reduces hight and width of the image by a factor of 4.

From the VGG19 you can see that first two layers apply convolution on top of the full 224x224 image which is quite expensive. If you apply similar calculations as I did above you will find that first layer does ~170M FLOPs, but it produces 64x224x224 output from the 3x224x224 image. Since layer applies the same conv filter you should see that number of FLOPs should be close to 170M * (64 / 3). In fact, it's almost 3.7B FLOPs. This layer alone has roughly as many FLOPs as whole Resnet-34. In order to avoid this computational problem in the Resnet they address this issue in the first layer. It reduces number of row and columns by a factor of 2 and it uses only 240M FLOPs and next max pooling operation applies another reduction by factor of 2.
In contrast, these four convolutional layers in the VGG19 make around 10B FLOPs.
Next, convolutional filters in the Resnet build up slowly. You can see that they use less kernels compare to the VGG, but they have more of them stacked alternating between convolutional operation and non-linear activation functions. That's another thing that was pointed out by @mrgloom. They exploited idea of using thinner, but deeper networks.

Next Resnet layers follow the same strategy, trying to make it thinner and deeper.
In addition, from Table 1 in the paper you can notice that convolutional blocks for Renet 50, Resnet 101 and Resnet 152 look a bit different. That's how it looks visually.
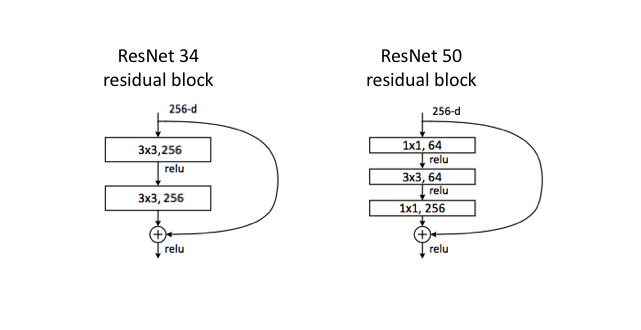
It was used in order to reduce number of operations even more, while using networks with larger number of filters in the convolutional layers. The idea of 1x1 convolutional layer allow to reduce channel depth before applying 3x3 convolution and upscale it back afterwords.
Does this mean that for each one of the 9(k) anchor types the particular classifier and regressor are trained with minibatches that only contain positive and negative anchors of that type?
No. RPN is looking whether any bounding box candidate (anchor) contains object of any known type or not. They call it objectness score in the article. The actual class of an object is considered in the loss function where a prediction of a class contributes to the loss (see $L_{cls}$ in Eq 1 on page 3 in the article).
Regarding your question, if you have 9 classes then the network will not be trained 9 times, but the cls layer which has 2*k dimension on your image will be 9*k (2 represents binary classification, 9 the number of your classes).
What is the role of anchors?
Your confusion was perhaps caused by the term anchor as you mention specific anchor type. Anchor types are not directly coupled with object types. As the article says, an anchor is a rectangle and anchors differ by their scale and aspect ratio so that for each region, different types of boxes (anchors) are tested (the blue ones on your image). This is because a car might require a different bounding box than a person. Of course, in practice, you will select these k box shapes (anchors) so that they would cover all your desired object shapes.
Whether an anchor is positive or negative, is determined by the loss function. Positive anchor is the one that 1) has highest overlap (IoU) with any ground truth bounding box or 2) its IoU overlap is above 0.7. Negative anchor is a box whose IoU is below threshold 0.3 for all ground truth boxes. The rest of the anchors are ignored in the loss function. As you see, this also allows the network to consider all of yours classes in one go (as bounding boxes from different object types are considered).
Multi-class classification is indeed difficult to understand from the paper as the authors are using only binary classifier in their own example.
Best Answer
Anchors Explained
Anchors
For the time being, ignore the fancy term of "pyramids of reference boxes", anchors are nothing but fixed-size rectangles to be fed to the Region Proposal Network. Anchors are defined over the last convolutional feature map, meaning there are $(H_{featuremap}*W_{featuremap})*(k)$ of them, but they correspond to the image. For each anchor then the RPN predicts the probability of containing an object in general and four correction coordinates to move and resize the anchor to the right position. But how does the geometry of anchors have to do anything with the RPN?
Anchors Actually Appear in the Loss function
When training the RPN, first a binary class label is assigned to each anchor. Anchors with Intersection-over-Union (IoU) overlap with a ground-truth box, higher than a certain threshold, are assigned a positive label (likewise anchors with IoUs less than a given threshold will be labeled Negative). These labels are further used to compute the loss function:
$p$ is the classification head output of the RPN that determines the probability of the anchor to contain an object. For anchors labeled as Negative, no loss is incurred from regression — $p^*$, the ground-truth label is zero. In other words the network does't care about the outputted coordinates for negative anchors and is happy as long as it classifies them correctly. In case of positive anchors, regression loss is taken into account. $t$ is the regression head output of the RPN, a vector representing the 4 parameterized coordinates of the predicted bounding box. The parameterization depends on the anchor geometry and is as follows:
where $x, y, w,$ and h denote the box’s center coordinates and its width and height. Variables $x, x_a,$ and $x^*$ are for the predicted box, anchor box, and ground-truth box respectively (likewise for $y, w, h$).
Also notice anchors with no label are neither classified nor reshaped and the RPM simply throws them out of computations. Once the RPN's job is done, and the proposals are generated, the rest is very similar to Fast R-CNNs.